[ Rubust CNN-based Gait Verification and Identification using SGEI ]
( 1 ) ........ [ SGEI ] Skeleton Extraction & Gait Period Analysis ( 현재글 )
이 논문에서는 보행자의 Skeleton을 OpenPose Network를 통해 얻어낸 후 , 보행자의 다리를 하나의 Pendulum으로 가정하고 회전 각을 계산하여 Gait Period ( 보행 주기 ) 를 계산한다. 이후 한 주기 동안의 Silhouette Image들과 Skeleton을 이용하여 SGEI를 만들어낸다. 이를 통해 보행자의 옷, 들고있는 물건 등의 외형 변화에 따른 영향을 제거하는 것이 목표이다.
- Skeleton Extraction
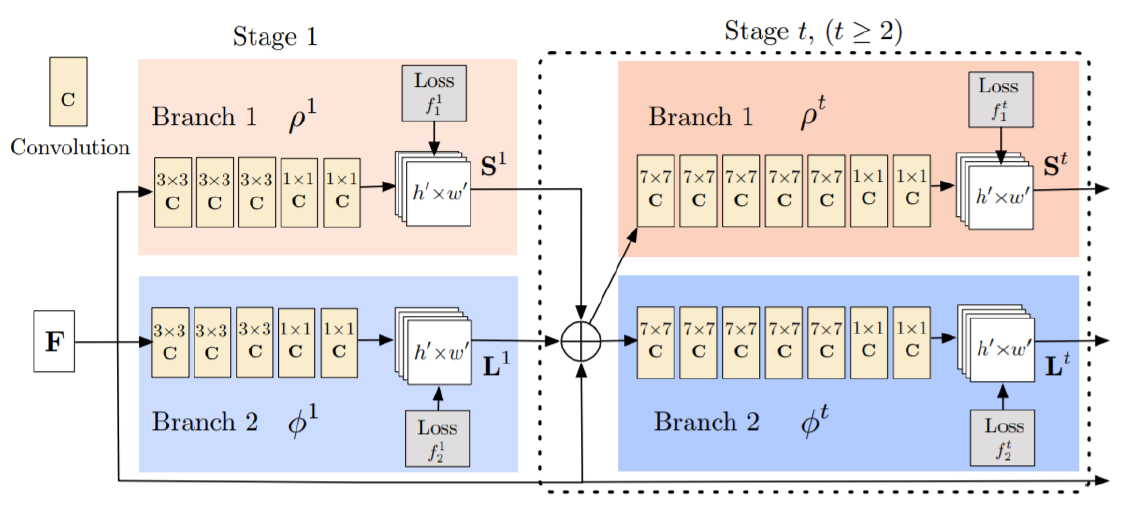
먼저 위 그림은 OpenPose Network의 Architecture이다. 2개의 Branch로 구성되어 있고 Stage를 직렬로 연결한다. 하나의 Branch는 Part Confidence Maps을, 다른 Branch는 Part Affinity Fileds를 예측하는 구조이다. 본 논문에서는 OpenPose Network에 대한 자세한 설명을 생략하겠다. 그에 관한 내용은 아래 링크를 참고하면 좋을 것 같다.
○ OpenPose : https://blog.naver.com/worb1605/221297566317
- Gait Period Analysis
입력으로 들어오는 개개인의 Gait Sequence는 길이가 각각 다를 수 있다. 찍힌 시점에 따라 시작 Frame에 Gait Cycle이 시작될 수도 있고, Gait Cycle의 중간부터 시작해서 이어질 수도 있다. 동일한 조건에서 Gait Feature를 뽑아내야 유리하기 때문에, 한 주기를 측정하기 위해 보행자의 다리를 Pendulum으로 가정한 후 각도를 이용한다.
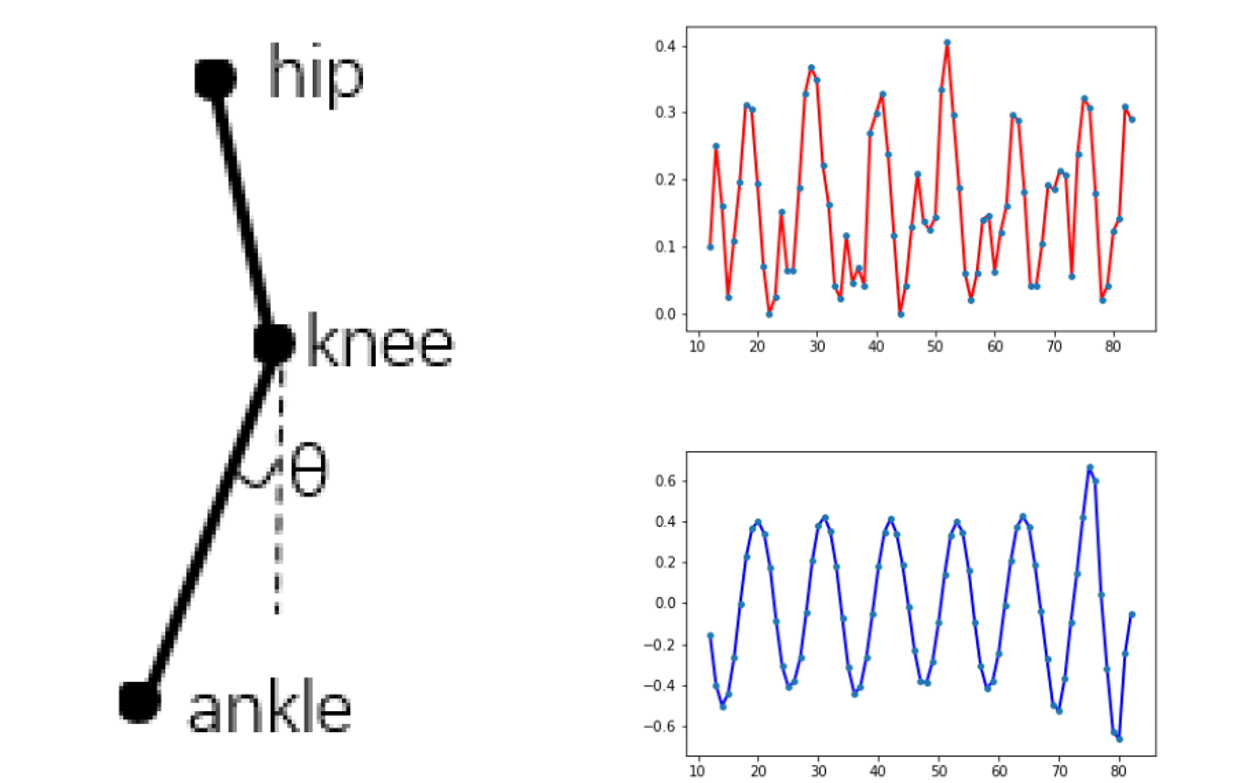
위 그림을 보면, 다리를 하나의 Pendulum으로 가정한 후, 무릎에서 발목까지의 Vector와 무릎에서 지면으로의 수직 Vector사이의 각도를 측정하여 오른쪽 위의 Signal을 만들어 낸다.
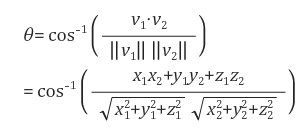
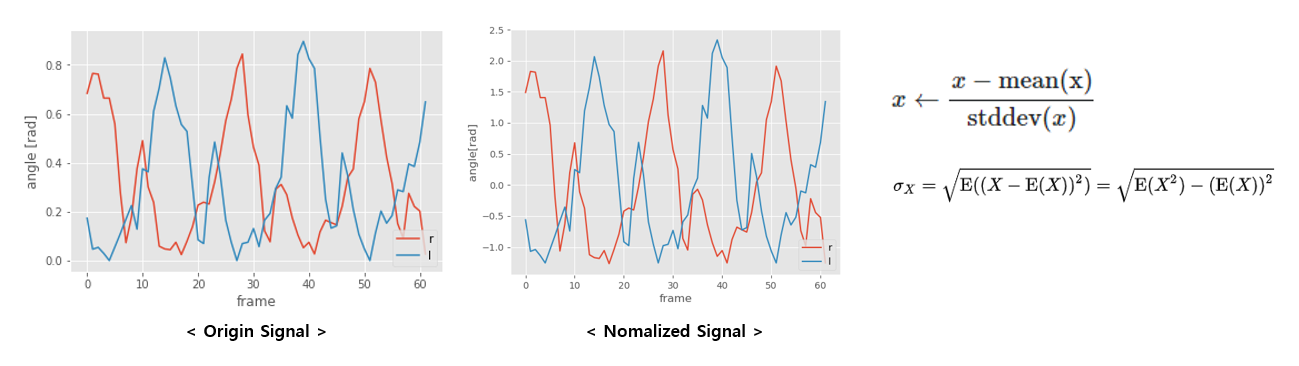
위 수식을 통해 Vector 사이의 각을 구할 수 있다. 하지만 이렇게 뽑아낸 Signal Graph만 보고 Gait Period를 측정하는 건 쉽지 않다. 따라서 논문에서는 normalization, mean filtering, autocorrelation등의 과정을 통해 오른쪽 아래의 파란 Signal을 만들어 내었다. 그 과정은 아래와 같다.
○ Normalization
먼저 평균 (mean) 값으로 빼준 후 Standard deviation으로 normalization하면 된다. 직접 CASIA-B Dataset을 통해 진행해본 결과는 아래와 같다.
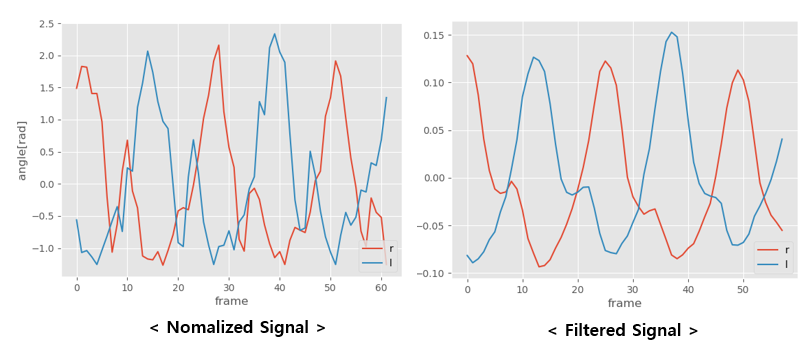
○ Mean Filtering
다음으로 평균 Filter를 통과시킨다. 정해진 크기의 window를 움직여가면서 window 내의 값을 평균하여 출력하는 Filter이다. Edge에서의 처리에 따라 결과가 다른데, 주변 값을 활용하여 Extension해주거나 Periodic Signal의 경우 그냥 반대편에서 Data를 가져다 ( 앞 부분엔 뒤의 Data, 뒷 부분엔 앞 쪽의 Data, 환형 Queue를 생각하면 쉬울 듯 ) 쓰는 경우도 있다. 하지만 앞서 말한대로 어떤 Gait Cycle 동작에서 시작할 지 모르므로, 그냥 채워주지 않고 사용했다.
○ Autocorrelation
마지막 단계는 Autocorrelation이다. correlation이란 두 Signal 사이의 상관성을 따져볼 때 사용되는 개념이다. 시계열 Data에서는 현재의 상태가 과거 또는 미래의 상태와 연관지어 생각할 수 있는 경우가 많다. 이럴 때, 시간 이동된 자기 신호화의 상관성을 Autocorrelation이라고 한다.
몇 가지 주요한 특징이 있는데,
1. Autocorrelation은 대칭적이다.
2. 원점에서 최고점에 도달
3. 주기적 SIgnal은 그 주기성을 유지한다.
시간 이동된 자기 신호화의 상관성을 따질 수 있기 때문에, Peak만 찾으면 주기를 알 수 있게 되고, 주기성을 유지하기 때문에 더욱 좋다.

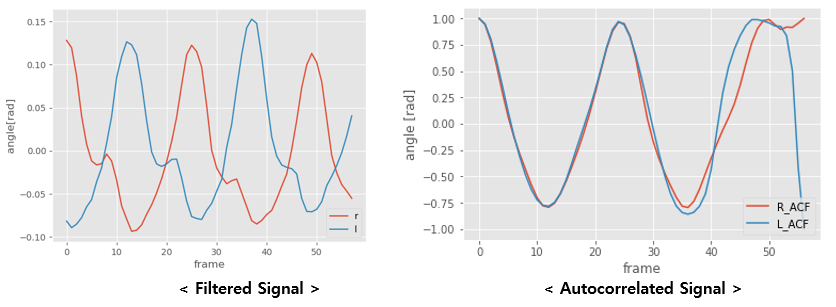
오른쪽의 Graph를 보면 오른쪽, 왼쪽 다리를 각각 계산해 보았을 때의 Graph이다. Peak부터 Peak까지의 Frame 수를 주기로 생각하고 사용할 수 있다.
- SGEI
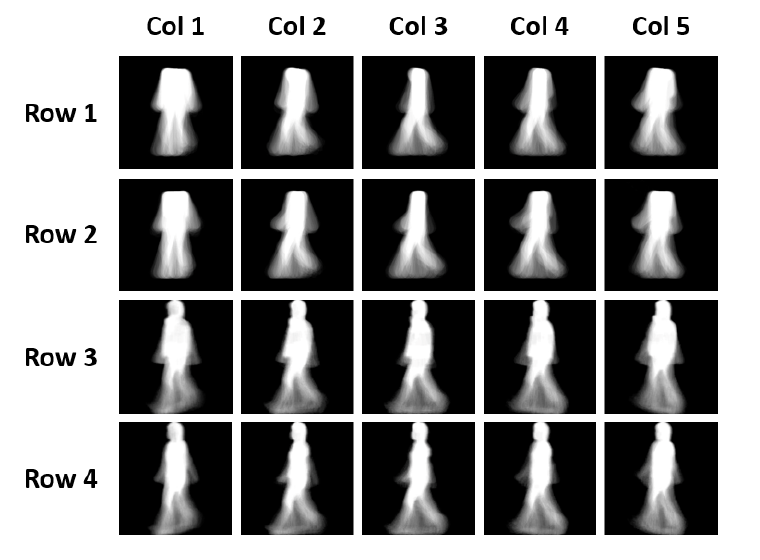
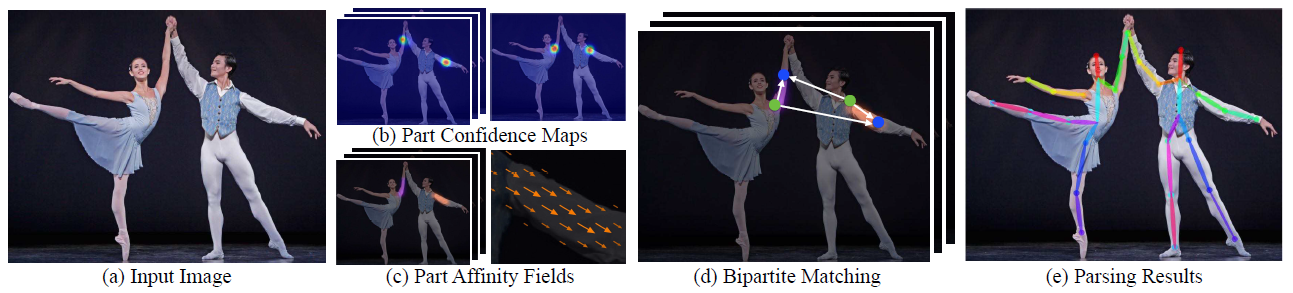
위 그림의 1, 2 Row는 SGEI 3, 4 Row는 GEI를 나타낸다. SGEI를 만들 때에는 Skeleton Extraction을 통해 얻어낸 Body Part Point에 17 pixel radius의 원을 그리고 Body Part 간의 연결을 35 pixel의 width를 가진 Rectengle로 Skeleton을 그린 후 한 주기의 Silhouette Image를 입력으로 받아 SGEI를 만들어낸다.
다음 글에서는 SGEI를 이용해 Gait Verification 과 Identification을 하는 과정에 대해 알아보겠다.
- 참고자료
- Robust CNN-based Gait Verification and Identification using Skeleton Gait Energy Image
- OpenPose : Realtime Multi-Person 2D Pose Estimation using Part Affinity Fileds